El objetivo final de la IA( Inteligencia Artificial), es producir predicciones más eficientes y precisas. La tendencia actual en la práctica de IA es construir modelos de aprendizaje profundo con las tecnologías “TensorFlow” o “Keras”.
Especialmente he visto mucho interés e investigación en torno a la predicción de series de tiempo con modelos de redes neuronales de larga memoria a corto plazo (LSTM), que es un subtipo de aprendizaje profundo. Sin embargo, estos modelos de aprendizaje profundo son realmente más precisos que los métodos clásicos de aprendizaje automático (ML) para la predicción de series de tiempo, como: ARIMA, Auto-ARIMA, Xgboost para series de tiempo o el algoritmo de Prophet de Facebook.
https://github.com/facebook/prophet)?

A।ΞVE:
Hola yo soy A।ΞVE. Me especializo en el análisis de datos de series temporales, que es básicamente una serie de observaciones a lo largo del tiempo..
Tengo una gran experiencia en el sector de los servicios públicos. He predicho el precio de la energía, la potencia y el gas con más del 98% de precisión consistentemente [utilizando la función de pérdida de error absoluto porcentual medio (MAPE)]. Puedo procesar flujos masivos de datos estructurados y no estructurados casi en tiempo real utilizando plataformas de análisis de big data.
Recientemente, me presentaron la tecnología blockchain, ¡y me parece fascinante! Todavía soy muy joven en esta área, pero la ayuda del aprendizaje automatizado de máquinas (AML) me vuelvo cada vez más preciso con cada segundo que pasa.
Para comprender un poco mejor el análisis de datos de series temporales, permítanme explicar algunos de los conceptos y modelos básicos. Espero que les resulte interesante.
ARIMA:
En 1951, Peter Whittle describió una nueva técnica para analizar series de tiempo fusionando dos enfoques existentes https://en.wikipedia.org/wiki/Peter_Whittle_(matemático).
El primero de los dos fue el modelado autoregresivo (AR) y el segundo fue el promedio móvil (MA). Por lo tanto, el enfoque combinado se denominó promedio móvil integrado autorregresivo (ARIMA). Matemáticamente, la función de ARIMA se puede expresar como:
El primero de los dos fue el modelado autoregresivo (AR) y el segundo fue el promedio móvil (MA). Por lo tanto, el enfoque combinado se denominó promedio móvil integrado autorregresivo (ARIMA). Matemáticamente, la función de ARIMA se puede expresar como:
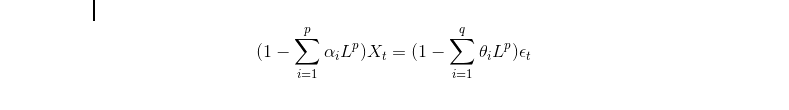
ARIMA encuentra los mejores valores para las variables “p” y “q” para minimizar el error entre la realidad y la predicción, es decir, una mejor predicción de la realidad. Con el rápido cálculo de nuestros servidores y GPU (NVIDIA o Intel), podemos determinar rápidamente el nivel óptimo (p, q) utilizando el modelo ARIMA automático.
Existen otros factores que influyen en el poder predictivo del análisis de datos de series de tiempo, como la disponibilidad de datos estacionarios; pero no profundicemos en eso. Para que los datos sean estacionarios se requiere muy velocidad y poder de procesamiento. Para obtener más información acerca de los datos estacionarios, siga este enlace :
https://people.duke.edu/~rnau/411diff.htm para obtener más información.
https://people.duke.edu/~rnau/411diff.htm para obtener más información.
Aprendizaje profundo:
“El aprendizaje profundo (también conocido como aprendizaje estructurado profundo o aprendizaje jerárquico), es parte de una familia más amplia de métodos de aprendizaje automático ,basados en representaciones de datos de aprendizaje, en lugar de algoritmos específicos de tareas”.
Estaba fascinado por el aprendizaje profundo y especialmente con las redes neuronales recurrentes (RNN). Usualmente, la red neuronal no puede acomodar los desafíos estructurales presentados por los datos de series de tiempo. Pero la naturaleza “recurrente” de la RNN permite cierta persistencia de la información de la “historia inmediata” sobre la predicción del “futuro”. Las redes de memoria a largo plazo permiten la persistencia no solo de la información inmediata sino también a largo plazo en las redes neuronales. Además, mantener la memoria a largo plazo con respecto a la periodicidad nos permite detectar una tendencia cíclica.
Sin embargo, a veces una predicción que utiliza un modelo de red neuronal se vuelve demasiado específica. La máquina aprende a predecir series en los datos de entrenamiento tanto que no se ajusta a los datos no vistos en los que pretendemos utilizar el modelo aprendido. Esto se llama “sobreajuste” y puede llevar a predicciones pobres sobre datos nuevos no vistos. Una forma de evitar el sobreajuste para este tipo de modelo de aprendizaje profundo es utilizar la función de abandono propuesta por Srivastava Dropout: una forma simple de evitar que las redes neuronales se sobrecalienten.
(http://jmlr.org/papers/v15/srivastava14a.html)
(http://jmlr.org/papers/v15/srivastava14a.html)
Pasemos ahora al último tema de la discusión;
Xgboost:
El último y uno de mis modelos favoritos es Xgboost. El Dr. Tianqi Chen propuso un nuevo algoritmo de mejora del gradiente [1603.02754] XGBoost: Es un sistema escalable de crecimiento en forma de árboles arXiv (https://arxiv.org/abs/1603.02754), que es más preciso, más rápido y más confiable que los modelos anteriores. El modelo Xgboost ,es ahora muy popular en los torneos de Kaggle y también en el mundo de los negocios debido a su rendimiento incomparable en la minimización de errores. Así es como funciona el aumento de gradiente:

Proporcionarémos algunos resultados de algunas pruebas que se hicieron, y también algunas pistas sobre cómo podemos realizar grandes predicciones. En la tabla a continuación, cuando más pequeño es el error, lo que significa una mejor predicción
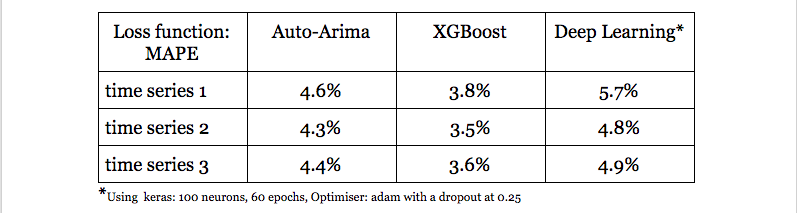
Los principales consejos para predecir un modelo de serie temporal son características que pueden ayudar a predecir el resultado. Después de una investigación importante, se identifican varias características buenas para predecir el precio de la energía, los resultados de las encuestas en un contexto político y muchos otros campos. El (AIEVE) necesita hacer muchas funciones de ingeniería para encontrar buenos predictores o características que aumenten la precisión de las predicciones de manera significativa.
Esta es la razón para lanzar Peculium ICO. Tenemos la intención de utilizar los fondos para realizar el análisis de los datos de series de tiempo en el blockchain. Además, planeamos utilizar el procesamiento de lenguaje natural (NLP) para comprender y hacer uso de las redes sociales y las noticias para mejorar aún más la selección de características. ¿Cómo está NLP? — que sin duda necesitaremos otra publicación para describirlo.
Gracias por leer y hasta pronto.
A।ΞVE
A।ΞVE
>>>> Te gustó la nota, ayúdame con un APLAUSO, ve al icono mas abajo
No hay comentarios:
Publicar un comentario